The Stock Ticker Service Design
I got pissed off by seeing system design interview videos on this. So I thought why not write a blog post about it. Why i got pissed off? I have watched a video on youtube about this.
This dude introduces a time series database infront of a stock ticker service. I mean come on, this is not a time series database, this is a stock ticker service. That is when i stopped watching this video.
When you design any system we need to understand the requirements first. So lets start with the requirements of a stock ticker service.
Functional Requirements
Real-time Stock Price Updates/ watchlist: The system should provide real-time updates of stock prices as they change. Don’t put too much drama we just need to get the stock price as fast as possible. Nothing more, nothing less.
Buy and Sell Stocks: Users should be able to buy and sell stocks.
Non Functional Requirements
High Throughput
Low Latency
Now first question do we really know what the difference between throughput and latency is? This is the first thing you need to understand before designing any system.
In simple terms, throughput is the number of requests your system can handle per second, and latency is the time it takes to process a request.
For example, if your system can handle 1000 requests per second, then your throughput is 1000. If it takes 200 milliseconds to process a request, then your latency is 200 milliseconds. Measurement unit of throughput varies from system to system, but it is usually measured in requests per second (RPS) , transactions per second (TPS) or MB/Sec. Latency is usually measured in milliseconds (ms).
Please check this https://github.com/mathewjustin/DesignPatternsAndAbhyasas/blob/main/LatencyAndThroughput.md
When it comes to stock ticker, i want to get the stock price as fast as possible. If NSE sends a stock price update at 10:00:00.000, i want to get that update at 10:00:00.200. This is the latency requirement.
Do you even think you can have a db that can give you this kind of latency? No, having a db or any kind of storage then reading from that and pushing to user will increase the latency my multifold. So whats the best way?
Lets think how NSE or BSE actually does this.
Which feature to implement first?
Lets take the watch list feature first.
This is interesting. Lets talk the numbers first. How many active users will be there in for our product?
Lets say we have 1 million active users. And they have an average of 10 stocks in their watchlist. So we have 10 million stocks in our watchlist.
Essentially if we have a simple rest api server is going to recieve a request every time a stock price changes. So if we have 10 million stocks, we will have 10 million requests per second. This is not going to work. We need to have a better way to handle this.
Solution
We can use a publish-subscribe model to handle this.
As a broker we will recieve stock price updates from NSE or BSE. We will then publish these updates to all the subscribers who are interested in that stock. This is what we ultimately want.
So the change in price should be sent to all the subscribers who are interested in that stock. We should not ideally have any storage in between. Like for example, we may think if NSE is returning same stock price update multiple times, we can store it in a db and then send it to the subscribers. But this is not a good idea. Introducing anything in between will increase the latency. So we should not have any storage in between.
Now what if have Kafka or any other message broker in between? This is a good idea. We can use Kafka to handle the publish-subscribe model.
But there is a catch latency and throughput. We are talking about micro second lantency. Kafka will have to write to disk. The message should reach a partition and then it should be read by the customer. This will increase the latency. So we should not use Kafka or any other message broker.
We need something which should be in memory and should be able to handle the publish-subscribe model. For a slow client we can actually drop the message. Zerodha’s design choice is like this. They use a in-memory data structure to handle the publish-subscribe model.
The zerodha way of doing this?
*I deep dived into Zerodha’s design choices. Particularly this blog from the Zerodha team: https://zerodha.tech/blog/scaling-with-common-sense/
Here, Kailash talks about the following on “10. Caching is a silver bullet, almost”.*, that is they use redis heavily. Also they optimize redis for the stock ticker service. What they do? They essentially turn off the persistance of redis. This means that redis will not write to disk. So it will be in memory and it will be fast. Also a lot many points caught my attention.
Then they have a go binary which handles hundreds of thousands of requests per second. This is a good design choice. They use a in-memory data structure to handle the publish-subscribe model.
I am kind of speculting that the design should be something like the below.
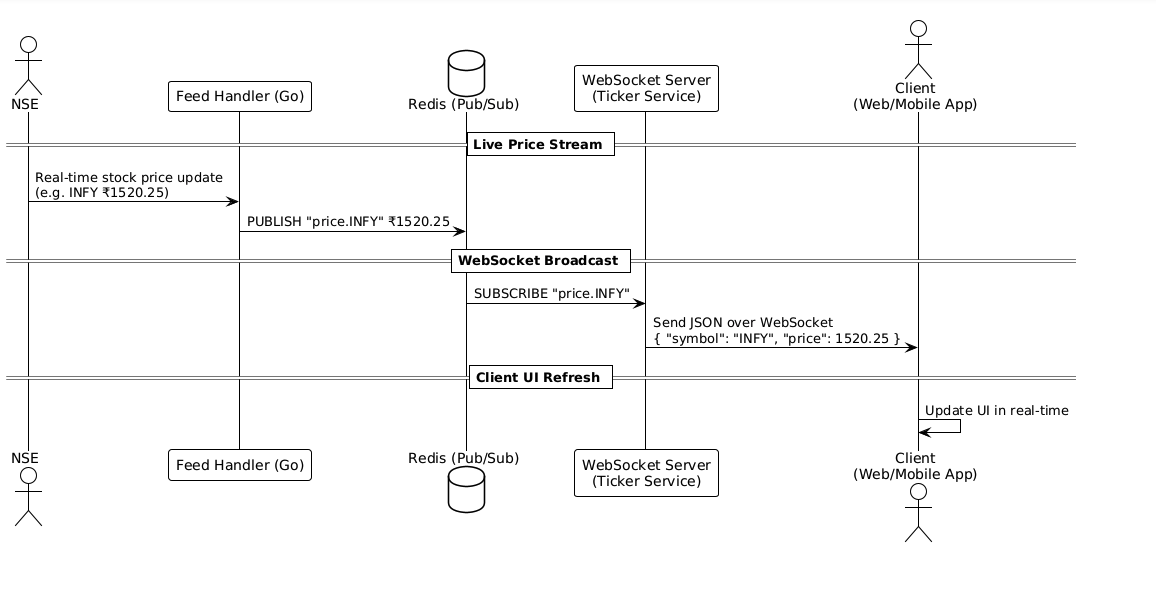
Essentially the websocket server fan-outs the stock price updates to all the subscribers who are interested in that stock. The websocket server is a go binary which handles hundreds of thousands of requests per second. The websocket server is connected to redis which is used to handle the publish-subscribe model.
Conclusion
What we learned?
- For a any service which needs to be low latency and high throughput, we should not have any storage in between.
- We must pick the right programming language for the service. Go is a good choice for this kind of service purely because of its performance. I believe java can also do well since the inception of its virtual threads.(More experimentation is needed)
- Switching off redis persistence, i frankly never thought of this. This is a good design choice. But we need to be careful about the data loss. If redis goes down, we will lose all the data. So we need to have a backup plan for this.